
Published June 15, 2026 in Meshub.ai
How to Test Prompts Across AI Models: A Practical Workflow

Share
If you want to know how to test prompts across AI models, start with a simple rule: do not judge a prompt by one answer from one assistant. A prompt that works well in one model may produce a weaker structure in another, while a prompt that seems too detailed for one task may be exactly what another model needs to preserve context.
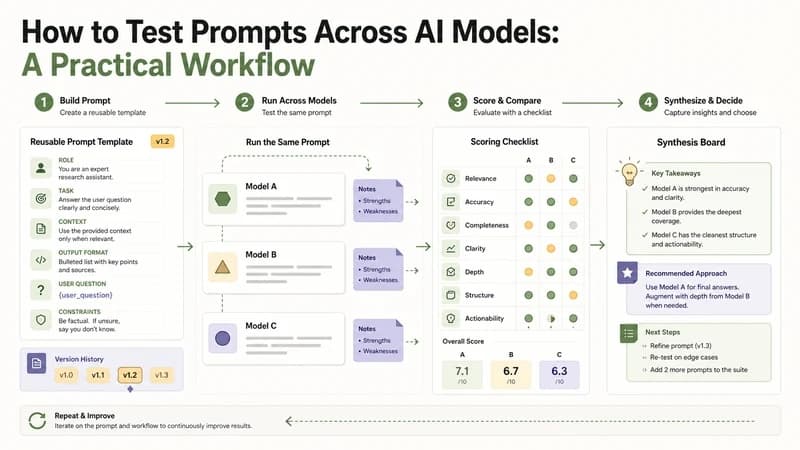
Prompt testing across AI models is a repeatable workflow for comparing the same instruction, context, and success criteria across multiple assistants. It helps you improve prompt quality, catch unclear instructions, and decide which model is best suited for a specific task. If you are new to multi-model work, Beginner's Guide to Multi-Model AI Platforms is a useful foundation before you build a testing routine.
How to Test Prompts Across AI Models Without Creating Noise
The goal is not to run every prompt through every model forever. The goal is to learn which prompt pattern gives you reliable, reusable answers for a particular workflow. A good prompt test isolates the variables. The task stays the same. The source material stays the same. The output format stays the same. The only major change is the model answering the prompt.
This matters because model comparisons become messy when every run changes at once. If you revise the prompt for one assistant, add examples for another, and change the output format for a third, the results will be hard to interpret. You may still get a useful answer, but you will not learn whether the prompt, the model, or the extra context caused the improvement.
Step-by-Step Prompt Testing Workflow
1. Define the task and success criteria
Write one sentence that explains what the prompt should accomplish. Then define what a good answer must include. For example, a research prompt might need a concise summary, uncertainty flags, practical implications, and a list of items to verify. A writing prompt might need a specific audience, tone, structure, and length.
2. Create a reusable prompt template
A prompt template prevents your test from becoming improvised. Include the role, task, context, constraints, output format, and quality bar. Keep the model names out of the prompt. You want the prompt to be portable across assistants and useful in future runs.
3. Choose two or three models for the first test
Testing too many models at once can slow the workflow and create comparison fatigue. Start with two or three assistants that you already use or are considering. For each model, paste the same template and the same context. Do not provide extra hints to one model unless you plan to run the same revision round for every model.
4. Score the first answers with a rubric
Use a short rubric before you begin reading too casually. Score relevance, completeness, structure, factual caution, actionability, and format fit. For team workflows, add a field for "review effort" because a polished response is not always the easiest response to verify or reuse.
5. Run one controlled revision round
After the first scoring pass, write one revision instruction and send it to each model. Keep it identical. This step shows whether the prompt is easy to steer. Some models may respond better to explicit constraints, while others may improve more when you provide examples or a clearer output format.
6. Synthesize the final prompt pattern
The output of a prompt test is not only the best answer. It is the improved prompt pattern. Save the template, the scoring notes, the strongest answer, and the failure modes you noticed. Over time, this becomes a practical prompt library instead of a scattered collection of one-off chats.
Prompt Test Checklist
- The task has one clear objective.
- All models receive the same source context.
- The output format is specified before the first run.
- The scoring rubric is written before reading the answers.
- Revision instructions are identical across models.
- Unsupported claims and uncertainty are tracked.
- The final prompt pattern is saved for reuse.
Prompt Testing Scorecard
| Score area | Question to ask | Why it matters |
|---|---|---|
| Relevance | Did the answer solve the stated task? | A fluent answer can still miss the intent. |
| Completeness | Did it include the required sections and constraints? | Missing pieces create extra editing work. |
| Factual caution | Did it mark uncertainty and avoid unsupported claims? | This is critical for research, strategy, and public content. |
| Structure | Was the output easy to scan and reuse? | Reusable structure saves time after the chat ends. |
| Actionability | Could a person use the answer for the next step? | Practical workflows need decisions, not only explanation. |
| Revision response | Did the model improve after the same feedback? | Steerability is part of real prompt quality. |
What to Do When Models Disagree
Disagreement is not a failure. It is a useful signal. When two models produce different answers, separate the difference into categories: missing context, different assumptions, different structure, unsupported claims, or genuinely different recommendations. Then decide what should be verified by a human, a primary source, or a subject matter expert.
This is especially useful in research and content workflows. One assistant may produce a stronger outline, while another may surface a risk or question the first answer missed. A multi-model prompt test lets you combine strengths without assuming that the first confident answer is the final answer. The workflow in AI Research Workflow: From Questions to Insights shows how this review habit can fit into a broader research process.
How Meshub.ai Helps
Meshub.ai helps users discover AI tools and think about AI work as a system. Prompt testing across AI models is easier when you can evaluate tools by use case, compare workflows, and keep track of where each assistant fits. The point is not to collect more apps. It is to build a reliable path from prompt to answer to reviewed output.
For teams, Meshub.ai can support a practical testing mindset: choose the task, compare answer patterns, note where each model is useful, and turn repeated prompts into reusable workflows. When AI usage expands beyond individual experimentation, What to Compare When AI Usage Scales adds a broader framework for evaluating tools, reliability, and operational fit.
A Simple Example Prompt Template
Use a template like this as a starting point: "You are helping me complete [task] for [audience]. Use only the context below. Produce [format]. Include [required sections]. Flag anything uncertain. Do not invent facts. End with [next action]. Context: [paste source]." The exact wording should change by workflow, but the structure keeps the test fair.
After you run the same template across models, revise only the weakest part. If answers are too broad, add sharper constraints. If answers are too generic, add audience and examples. If answers invent details, add stronger grounding rules and require uncertainty notes. Each test should teach you something about the prompt, not just the model.
FAQ
Why should I test prompts across AI models?
Testing prompts across models helps you see whether an instruction is clear, portable, and reliable. It also reveals differences in structure, assumptions, and answer quality.
How many AI models should I test at once?
Start with two or three models. That is usually enough to find useful differences without turning the process into a slow review project.
What should a prompt testing rubric include?
Include relevance, completeness, structure, factual caution, actionability, format fit, and response to revision feedback.
Should I change the prompt for each model?
Not in the first round. Use the same prompt first so the comparison is fair. Later, you can create model-specific variants if the workflow benefits from them.
Can prompt testing reduce AI hallucinations?
It can help identify unsupported claims and inconsistent answers, but it does not replace verification. Use model disagreement as a reason to check important claims.


